Need help getting the results from LLM?
version: 1.00 Date: 29/05/2024

Do you need help to get the answers you want from large language models? If so, this post is for you. I'll guide you on effectively communicating with LLMs, increasing the likelihood of getting your desired answers. Remember, you are not talking to a human; you must learn to speak with the LLM in a way the LLM requires to get the best results. The providers of LLM are improving the experience and are continually to improving the LLM to be more human-like in these capabilities, and we are getting better, but to get the correct results from an LLM, the following will go a long way; let's dive in.
Selecting the right LLM is critical to achieving the desired results. Each LLM is unique, and the outcomes they produce can vary significantly. This variability directly results from the specific training each LLM has undergone. Through extensive testing, I've found that to harness the most accurate and beneficial results, you must choose a model that aligns with your expectations. Your choice matters, whether it's OpenAI 4o, the Microsoft deployed versions, or Antropic Opus for general day-to-day AI activities. I've tested thousands of prompts across various models and selected these to provide the most accurate results.
The secret to speaking with a large language model is to be short and direct. First, the model is not a human, so you always need to be explicit about what you want from the model and forget to be polite. This means you must be direct in what you want from the model and never add please, thank you, etc. The large language model has no feeling, and adding unneeded word tokens with please, thanks, or other niceties adds to the query complexity and the model having to spend time matching these unneeded word tokens.
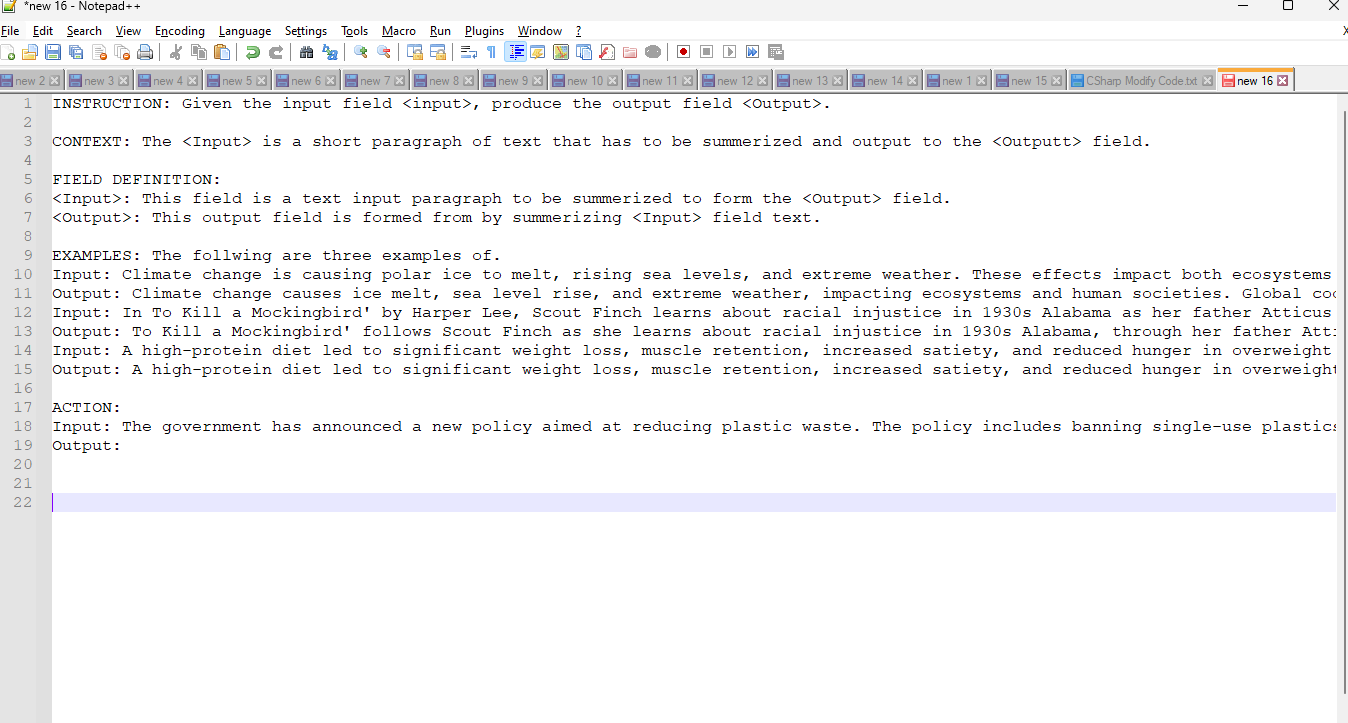
Next, be extremely careful to avoid buying into finding prompts on the internet that claim to be what you need. If you want to know if a prompt is valid, use what you learn in the post as a gauge to tell if the prompt is valid. A prompt for an LLM should have the following elements: Instruction, Context, Input Description, Output Description, Examples.
Instruction: It needs to be short, short, short. It is enough: the LLM is not a human but is trying to predict based on your input and output. The more you give it, the more confusing you can make it, and the more you can mislead the LLM. Focus on the quality of instruction rather than the length. For many projects, I will start with the instruction, 'For the following input, create an output.'. Here, you are telling the LLM that it needs to create an output from the given input. You can add a further short line like 'Take the input and summarize it to form the output'. Here, see how explicit the instruction is. First, I told the LLM explicitly that its job was to form an output from the input, no fluffing around, just clarity. Then, I asked the LLM how-to for the output from the input. So, in the first two lines, I have set the LLM up to clearly explain, given the input, how to create the output.
Context: Next, we give the LLM some context to help align it internals. For example, as the LLM predicts the output text, by giving contest meas, other words in those areas will be related. Remember, the LLM is trying to predict text, and by providing context, you are refining the internal high-order space it will print. Internally, in the LLM model, there is a multi-residential space where words (tokens) are grouped, and words like dog, veterinary, and food are grouped together. By setting contact and again keeping it short, you get the LLM to look at the phrases that are close to each other. Again, this context test needs to be about one line long.
Input: Describes the input; for example, '<input> is a paragraph of text to be summarized to form the <output>.' Again, it is short, clean, and direct. This single line tells the model the input and how to use it. Here, I am using a placeholder; I selected this type of placeholder as it's an HTML tag, and something the model has been trained on extensively will be HTML data.
Output: Describes the output; for example, '<output> is a summary of text to be summarized to form the <input>.' Again, it is short, clean, and direct. This single line tells the model the output format and output; again, I am using a placeholder the model has been trained extensively on, HTML format, and text.
Examples: Here, you need to provide examples to have a line of text like, 'The following are three examples:' and you will give the model three examples of the inputs and outputs. This grounds the LLM and helps it form the output you want, the following screen shot shows how we put it together and sent this to the LLM.