
Looking back at today's AI, will seem so primitive.

Looking ahead, our current methods of interacting with AI—crafting a prompt and awaiting its response—will seem primitive, akin to using a horse for plowing fields, when compared to today's agriculture capabilities. Consider the potential for AI to place the AI model directly on silicon and optimize it for inference, this would mean an order of magnitude faster of even mode. What would this order of magnitude mean?
The total cost of inference would be reduced, and as a result, the expense of performing thousands of inferences every minute would become negligible. Imagine the implications: running thousands of inferences cheaply and rapidly—how would this revolutionize our current AI applications. AI's role would shift from merely responding to prompts to actively integrating into our immediate tasks, providing instantaneous edits, suggestions, feedback, and even taking autonomous actions. Tasks and feedback would be generated in anticipation of your next actions, offering numerous possibilities for your subsequent steps before you even proceeded.
Take writing a blog post, for example. As you begin typing, your input is sent to the AI at speeds much faster than today's standards, giving it context to aid your writing. In the margins, suggestions for subsequent sentences and paragraphs appear, along with stylistic alternatives for your text. You would be talking and brainstorming while writing with the AI, feedback would be verbal, textual, and contextual to what you were doing, feedback from the AI would happen in context to your application and all in real time to your working pace, while the content dynamically evolves, with citations from various sources being integrated.
AI in team meetings would be able to interact with the team, in context and provide valuable feedback by accessing real time data relevant to the meeting and providing it in natural spoken language. Data, feedback, and real time reports generated on possible future outcomes based on different decisions the team has to make, all laid out for the team to happen in real time.
What if this wasn't just theoretical? A company named Etched has developed a silicon ASIC that dramatically enhances AI's speed, making today's silicon seem as antiquated as a valve radio. Meet Etches silicon It creates the transformer architecture directly on the silicon, and the result is one order of magnitude faster than the fastest GPU we have today.

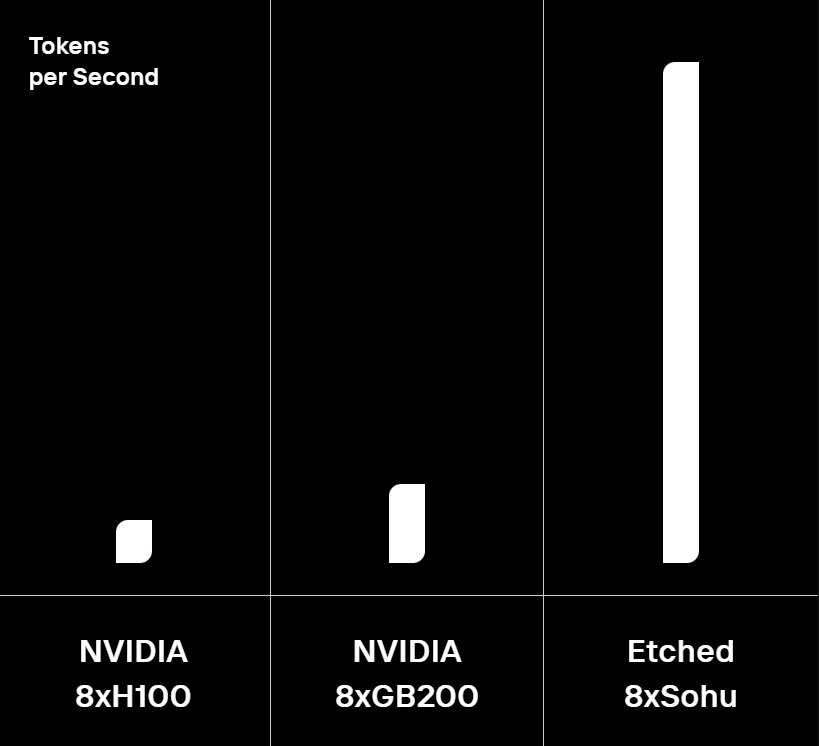
Just look at the inference speed difference, this advanced Etched silicon allows for rapid, repeated inferences, enabling real-time responses and the ability to refine outputs significantly faster than current capabilities. Our relationship with AI is transitioning to real-time interactions, with the capacity to perform hundreds of inferences to achieve a single refined output while continuously integrating new data.
We are currently limited to thinking in terms of one inference per second. Once we surpass this limitation, envisioning hundreds, millions, or even trillions of inferences per second, our approach to computing transforms. We begin to view each inference not just as a computation but as a guide, with the outcome of one serving as the input for the next, all within microseconds. This fundamental shift alters how we currently engage with AI.