
Diving Deeper into How Moshi is Built - Part 1 (Audio)
![Mosh].png](https://keithtobinblog001.blob.core.windows.net/www/Mosh].png)
In this post, we'll explore the technology choices behind Moshi's audio processing by Kyutai. Although I don't have insider access, I gained insights by examining the browser activity when using the Moshi demo. The browser is an excellent starting point for this in-depth look at Moshi.
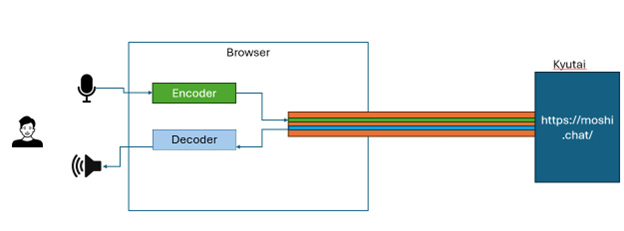
Traditionally, interacting with language models has involved a walkie-talkie approach: pressing a button to record audio, releasing it to send the audio to a server for processing, and receiving a response. An improvement on this method is to use software to detect pauses, eliminating the need for a button.However, this method is not natural for human conversation. When you access the Moshi demo, several JavaScript files load, initializing and opening a WebSocket to the remote server. You can observe this WebSocket connection to the remote server.

These JavaScript files also configure the browser's audio system using the Web Audio API. They create a custom instance of AudioWorkletProcessor and two instances of AudioWorklet for audio encoding and decoding. These AudioWorklets encode audio from your device's microphone and decode audio received from the remote server to your device's speaker.
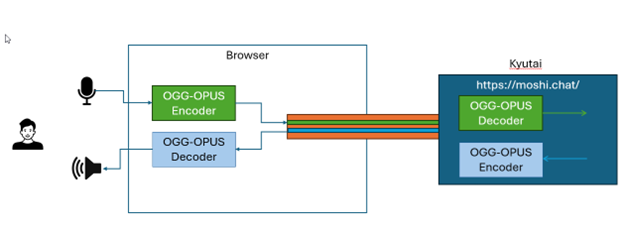
Could it really be that simple? Let's dig deeper. The browser's encoder and decoder, implemented as AudioWorklets, are powerful OGG-OPUS encoder and decoder. OPUS, a BSD-licensed audio codec, allows high-quality audio encoding and decoding with low bandwidth, low latency, and adjustable bit rates. This means OPUS can compress audio for transmission to the server and decode received audio efficiently, maintaining bandwidth and audio quality while minimizing latency. It also processes background noise removal.
The OPUS AudioWorklets are implemented in C/C++ using the Emscripten toolchain for WebAssembly. These modules load when you start chatting with Moshi, providing high-speed audio encoding and decoding. Each encoder/decoder includes JavaScript modules for setup and configuration.A notable aspect of this solution is the use of OGG-OPUS for full-duplex, compressed, variable bitrate audio streams over a single WebSocket. WebAssembly ensures fast audio processing. With OPUS, latency is capped at 23ms, leaving around 150ms for the remote language model's response. This low latency and high-quality audio contribute to Moshi's natural conversational feel.
In Part 2, I will explore how Kyutai achieves such speed with the language model, including possible architecture and design. Keep in mind, my observations are based on external analysis, and more details will emerge once Moshi becomes open-source.